
The Project
This project captures and transcribes in real time an audio stream from a radio station (RAC1) and displays the most relevant fragments in a minimalist web interface. Everything is automated with Docker.
It also served to validate a simple capture, transcription, and filtering pipeline, and to see which pieces should be separated if the system needs to scale.
Access the Demo
👉 Try it: https://eurekatop.com/radioalert
👉 SSE Endpoint: https://eurekatop.com/radioalert/events
Backend: Automatic Transcription with Whisper
The core of the project is a Python script that listens to the stream as if it were a browser. At first, I tried using ffmpeg to capture the stream, but it failed because the station has anti-bot protections and the connection was not accepted.
As an alternative, I found that using httpx.stream() allows reading the audio stream without issues—as long as the request looks like a real browser's. That’s why you need to add some headers...
The script is split into two parts: one for capturing the stream and another for transcription and keyword filtering. This transcription runs in parallel with the stream capture, so there's no need to wait for it to finish before continuing to capture.
The audio is processed in 4-second chunks and transcribed using the optimized Whisper model (int8).
model = WhisperModel("/models/whisper-small", compute_type="int8")
segments, _ = model.transcribe(BytesIO(audio_data), language="ca")
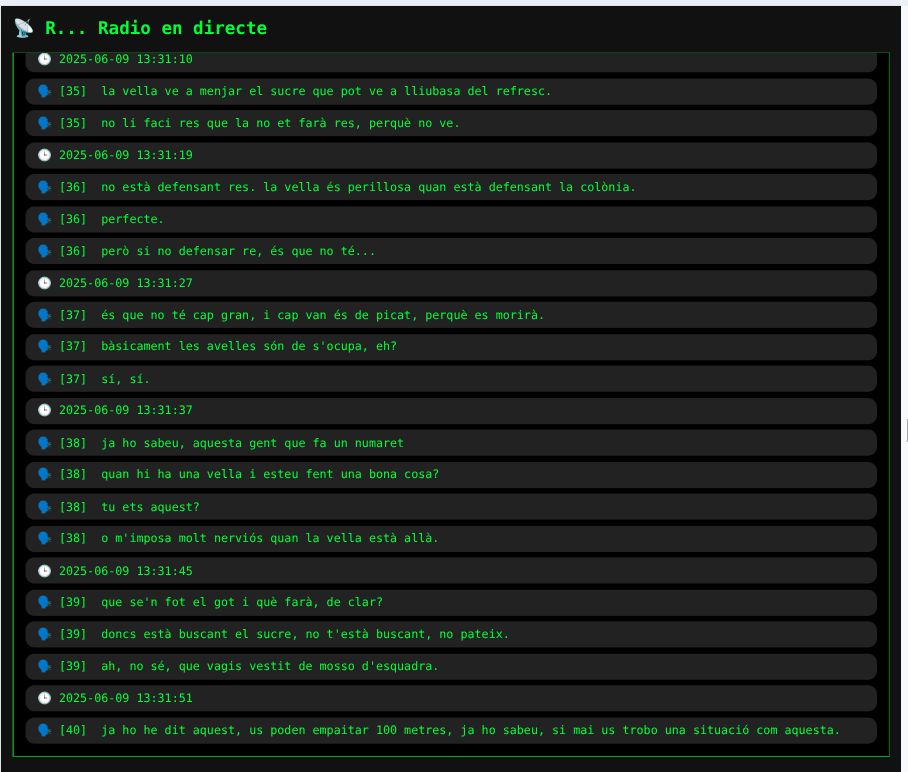
Once transcribed, it checks for keywords like “barça”, “avui”, or “lamine yamal”. If any are found, it triggers an alert and logs everything to a .log file. For example:
🕒 [2025-06-09 14:10:23] 🗣️ [12] avui a catalunya hem vist que...
🚨 🕒 [2025-06-09 14:10:23] ALERT: Keyword detected: avui
The system includes a short queue of previous audio to avoid cutting off sentence beginnings, since the model needs context to understand the stream correctly.
All of it is automated with Docker.
Frontend: Live Visualization
A small Node.js server displays the transcribed lines live from a .log file, sending them via Server-Sent Events to the terminal-style web interface.
fs.readFile(FILE_PATH, 'utf8', (err, data) => {
const lines = data.trim().split('\n').slice(-30)
lines.forEach(line => res.write(`data: ${line}\n\n`))
})
On the client side, the connection remains open with the browser's EventSource(), which automatically receives real-time updates:
const eventSource = new EventSource('/events')
eventSource.onmessage = function(event) {
console.log(event.data)
}
💡 Learnings
- Whisper is quite reliable, even in Catalan.
- Adding a buffer of previous audio improves accuracy in clipped sentences.
- With
httpx.streamand lightweight threads, you can capture audio stably without overloading the main process.ffmpegwas initially used but discarded to avoid anti-bot protections by simulating a real browser connection. - Server-Sent Events are a very simple yet effective tool to stream live data to a web app.
Stack and Techniques
- 🐍 Python + faster-whisper
- 📡 httpx for capturing audio streams
- 🎛️ Catalan transcription with the optimized Whisper-small model
- 🐳 Docker to encapsulate the service
- 🟩 Node.js + Express to expose the file as an SSE feed
- 🎨 HTML + CSS in terminal-console style
A vibe coding experiment by Francesc López Marió, 2025